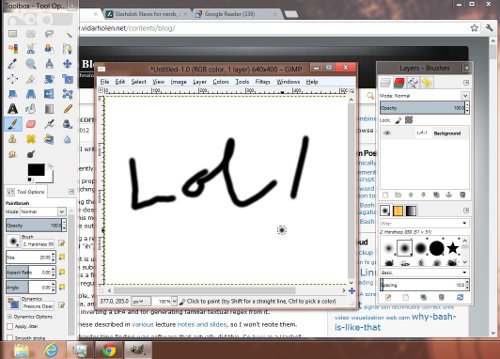
Shell scripting is notoriously full of pitfalls, unintuitive behavior and poor error messages. Here are some things you might have experienced:
find -exec fails on commands that are perfectly valid
0==1 is apparently true
Comparisons are always false, and write files while failing
Variable values are available inside loops, but reset afterwards
Looping over filenames with spaces fails, and quoting doesn’t help
ShellCheck is my latest project. It will check shell scripts for all of the above, and also tries to give helpful tips and suggestions for otherwise working ones. You can paste your script and have it checked it online, or you can downloaded it and run it locally.
Other things it checks for includes reading from and redirecting to a file in the same pipeline, useless uses of cat, apparent variable use that won’t expand, too much or too little quoting in [[ ]], not quoting globs passed to find, and instead of just saying “syntax error near unexpected token `fi'”, it points to the relevant if statement and suggests that you might be missing a ‘then’.
It’s still in the early stages, but has now reached the point where it can be useful. The online version has a feedback button (in the top right of your annotated script), so feel free to try it out and submit suggestions!
There are a lot of howtos and tutorials for using data recovery tools in Linux, but far less on how to choose a recovery tool or approach in the first place. Here’s an overview with suggestions for which route to go or tool to use:
Cause
Outlook
Tools
Forgotten login password
Fantastic
Any livecd
This barely qualifies as data recovery, but is included for completeness. If you forget the login password, you can just boot a livecd and mount the drive to access the files. You can also chroot into it and reset the password. Google “linux forgot password”.
Accidentally deleting files in use
Excellent
lsof, cp
When accidentally deleting a file that is still in use by some process — like an active log file or the source of a video you’re encoding — make sure the process doesn’t exit (sigstop if necessary) and copy the file from the /proc file handle. Google “lsof recover deleted files”
Accidentally deleting other files
Fair for harddisks, bad for SSDs
testdisk, ext3grep, extundelete
When deleting a file that’s not currently being held open, stop as much disk activity as you can to prevent the data from being overwritten. If you’re using an SSD, the data was probably irrevocably cleared within seconds, so bad luck there. Proceed with an fs specific undeletion tool: Testdisk can undelete NTFS, VFAT and ext2, extundelete/ext3grep can help with ext3 and ext4. Google “YourFS undeletion”. If you can’t find an undeletion tool for your file systems, or if it fails, try PhotoRec.
Trashing the MBR or deleting partitions
Excellent
gpart (note: not gparted), testdisk
If you delete a partition with fdisk or recover the MBR from a backup while forgetting that it also contains a partition table, gpart or testdisk will usually easily recover them. If you overwrite any more than the first couple of kilobytes though, it’s a different ballgame. Just don’t confuse gpart (guess partitions) with gparted (gtk/graphical partition editor). Google “recover partition table”.
Reformatting a file system
Depends on fs
e2fsck, photorec, testdisk
If you format the wrong partition, recovery depends on the old and new file system. Try finding unformat/recovery tools for your old fs. Accidentally formatting a ext3 fs to ntfs (like Windows helpfully suggests when it detects a Linux fs) can often be almost completely reverted by running fsck with an alternate superblock. Google “ext3 alternate superblock recovery” or somesuch.
Reformatting ext2/3/4 with ext2/3/4 will tend to overwrite the superblocks, making this harder. Consider PhotoRec.
Repartition and reinstall
Depends on progress
If you ran a distro installer and accidentally repartitioned and reformatted a disk, try treating it as a case of deleted partitions plus reformatted partitions as described above. Chances of recovery are smaller the more files the installer copied to the partitions. If all else fails, PhotoRec.
Bad sectors and drive errors
Ok, depending on extent
ddrescue
If the drive has errors, use ddrescue to get as much of the data as possible onto another drive, then treat it as a corrupted file system. Try the fs’ fsck tool, or if the drive is highly corrupted, PhotoRec.
Lost encryption key
Very bad
bash, cryptsetup
I don’t know of any tools made for attempting to crack a LUKS password, though you can generate permutations and script a simple cracker if you have limited number of permutations (“it was Swordfish with some l33t, and a few numbers at the end”). If you have no idea, or if your encryption software uses TPM (rare for Linux), you’re screwed.
Reformatted or partially overwritten LUKS partition
Horrible
LUKS uses your passphrase to encrypt a master key, and stores this info at the start of the partition. If this gets overwritten, you’re screwed even if you know the passphrase.
Other kinds of corruptions or unknown FS
Indeterminable
PhotoRec, strings, grep
PhotoRec searches by file signature, and can therefore recover files from a boatload of FS and scenarios, though you’ll often lose filenames and hierarchies. If you have important ASCII data, strings can dump ASCII text regardless of FS, and you can grep that as a last resort.
If you have other suggestions for scenarios, tools or approaches, leave a commment. Otherwise, I’ll wish you a speedy recovery!
Bash can seem pretty random and weird at times, but most of what people see as quirks have very logical (if not very good) explanations behind them. This series of posts looks at some of them.
# I run this script, but afterwards my PATH and current dir hasn't changed!
#!/bin/bash
export PATH=$PATH:/opt/local/bin
cd /opt/games/
or more interestingly
# Why does this always say 0?
n=0
cat file | while read line; do (( n++ )); done
echo $n
In the first case, you can add a echo "Path is now $PATH", and see the expected path. In the latter case, you can put a echo $n in the loop, and it will count up as you’d expect, but at the end you’ll still be left with 0.
To make things even more interesting, here are the effects of running these two examples (or equivalents) in different shells:
set in script
set in pipeline
Bash
No effect
No effect
Ksh/Zsh
No effect
Works
cmd.exe
Works
No effect
What we’re experiencing are subshells, and different shells have different policies on what runs in subshells.
Environment variables, as well as the current directory, is only inherited parent-to-child. Changes to a child’s environment are not reflect in the parent. Any time a shell forks, changes done in the forked process are confined to that process and its children.
In Unix, all normal shells will fork to execute other shell scripts, so setting PATH or cd’ing in a script will never have an effect after the command is done (instead, use "source file" aka ". file" to read and execute the commands without forking).
However, shells can differ in when subshells are invoked. In Bash, all elements in a pipeline will run in a subshell. In Ksh and Zsh, all except the last will run in a subshell. POSIX leaves it undefined.
This means that echo "2 + 3" | bc | read sum will work in Ksh and Zsh, but fail to set the variable sum in Bash.
To work around this in Bash, you can usually use redirection and process substition instead:
read sum < <(echo "2 + 3" | bc)
So, where do we find subshells? Here are a list of commands that in some way fails to set foo=bar for subsequent commands (note that all the examples set it in some subshell, and can use it until the subshell ends):
# Executing other programs or scripts
./setmyfoo
foo=bar ./something
# Anywhere in a pipeline in Bash
true | foo=bar | true
# In any command that executes new shells
awk '{ system("foo=bar") }'h
find . -exec bash -c 'foo=bar' \;
# In backgrounded commands and coprocs:
foo=bar &
coproc foo=bar
# In command expansion
true "$(foo=bar)"
# In process substitution
true < <(foo=bar)
# In commands explicitly subshelled with ()
( foo=bar )
and probably some more that I'm forgetting.
Trying to set a variable, option or working dir in any of these contexts will result in the changes not being visible for following commands.
Knowing this, we can use it to our advantage:
# cd to each dir and run make
for dir in */; do ( cd "$dir" && make ); done
# Compare to the more fragile
for dir in */; do cd "$dir"; make; cd ..; done
# mess with important variables
fields=(a b c); ( IFS=':'; echo ${fields[*]})
# Compare to the cumbersome
fields=(a b c); oldIFS=$IFS; IFS=':'; echo ${fields[*]}; IFS=$oldIFS;
# Limit scope of options
( set -e; foo; bar; baz; )
When someone with a modern, online, multi-gigabyte, multi-core tablet says “Oh darn, I can’t. I don’t have a computer with me”, something is tragically wrong. That’s why I can’t wait for Windows 8.
Three years later, an update:
Windows 8 sucked.
I still maintain that it was an awesome tablet OS in 2012, but it did not run on any good tablets. It still doesn’t. The Surface — thank the gods I never bought one — was heavy, bulky, loud and had terrible battery life. Surface 3 is better, but still nowhere near the state of the art.
Meanwhile, the ecosystem is quickly catching up. The value of running x86 Windows applications has dropped dramatically in the three years since this piece was written. Most of the other features that made Windows 8 interesting have been copied by iOS and Android — all the way down to the Metro design.
Today, a phone, a Bluetooth keyboard and a TV to cast to is actually a surprisingly good desktop replacement. And it’ll only get better.
RIP Windows.
I’m excited about Windows 8.
There, I said it.
I have five Linux devices in my home, I write Python in Vim on Ubuntu professionally, and I have rolled my eyes at every major shift in Windows since 3.11.
But I’m excited about Windows 8.
Before I ruin your day with my fanboy ramblings, let me clear up some reasons for why I don’t hate it (if you don’t either, feel free to skip towards the end).
“I don’t want a nerfed touch interface on my desktop!”
My actual Windows 8 desktop
Agreed. Fortunately, as you can see from this screenshot, a Windows 8 desktop session looks just like a Windows 7 one, with efficient, dense, touch hostile apps.
Believe me, I’ll be the first to scream bloody murder if I have to develop Windows software in a touch UI with only two apps on screen.
On that note, ARM based Windows 8 devices won’t support normal desktop sessions, so x86 is implied for the rest of the article. The reason for this should become apparent later.
“I want a start menu!”
Oh, that wonderful start menu
The start menu was awesome in 1998, when having 15 apps installed made you a power user. But now my entertainment PC (pictured) has 55 top level entries, and my development box has 92! In a tiny list with a huge scroll bar!
“But”, I hear you say, “that’s the full list! No uses that!”.
Quite right. The apps you love, you pin on the taskbar. This works exactly the same in Windows 8.
With your hands on the keyboard, you find by keyboard search. This works exactly the same in Windows 8.
This leaves the apps you use fairly often, which are either pinned to the start menu, or have bubbled their way up through frequent use.
Default 1080p start menu area
On a full HD display, the default is 20 items, with a maximum of 24. Shown in a linear list. The default uses literally less than a tenth of the available screen real estate (pictured).
On a smaller screen, you get 12-14 items, which is a very snug fit, and definitely not enough if you want shortcuts to web sites like I have on my Android and iOS devices.
So what do you do? Instead of having a short, narrow list on the left, we could lay them out in a grid (like desktop icons) to fit more of them.
And that pretty much describes the Windows 8 start screen!
Of course, you have tiles instead of icons, but I’ll get to those in a bit.
“Secure boot will block Linux and other OS!”
Maybe. I hope it doesn’t. I’m not saying it’s all cream and peaches, but hopefully it’ll continue to be optional on all devices.
Slimmer and faster!
There’s a running joke that both processing power and Windows boot time doubles every 18 months.
Windows 8, however, cold boots in 10 seconds on my low end, portable test hardware. It also uses about 30% less RAM than Windows 7.
No one is more surprised than me.
Tiles — Icons++
I no longer “check my email”, I get a notification when new mail is received. I no longer visit web sites regularly, I use RSS to tell me when there’s something new. Why should I still open my apps to see what’s happening?
Sure, my RSS reader could be an icon saying “RSS Reader”, but it would be more convenient if it said “Bitcoin market crashes, and 14 more”. Windows 8 does this.
My ebook reader could say “eBook reader”. Or it could say “Reading Dune, page 134 of 245”, with cover art instead of a generic icon. Windows 8 does this.
My video player could say “VLC”, or it could show a screenshot of where I stopped a video last night. Wait, *cough*, that’s a terrible idea. Windows 8 lets you disable this tile-by-tile!
A People app tile, plus two tiles representing two specific friends
One app can have multiple tiles. Just like how you can have two books on your desktop that open in the same reader, you can have two tiles. They’ll show the book title and page number separately.
For non-file based links, Win7 users can create shortcuts to invoke a program with different command line arguments (but no one does). With Windows 8, you can pin application specific contents, e.g. a Facebook contact, and have a tile representing them.
This tile will then show photos of that particular person (pictured), plus their recent activity and messages they send you. Great for close friends and people you’re dating (or stalking). When opened, you’ll go immediately to their page.
Likewise, you can have an icon for a specific Wordfeud game, showing current score and status. An often used playlist? A news source you follow closely? A specific alt in a mmorpg? Separate work and private email accounts? All available at a glance.
Is it worth an upgrade?
Honestly? While I think Windows 8 is an improvement in some ways, I probably won’t be upgrading my Windows 7 desktop/laptop systems any time soon.
However, (and here’s the twist), I will camp out a cold winter’s night to get a Microsoft Surface or similar Windows 8 tablet PC. Because you see, I consider Windows 8:
The hands down, best tablet PC OS to date
I don’t even care about Windows 8 vs GNU+Linux, I see Windows 8 tablets vs Windows desktops and iOS/Android tablets.
Why?
I hope I’ve convincingly argued that Windows 8 is not nerfed, but a complete desktop OS (“as far as Windows goes”, hurr durr).
Now, imagine that on a tablet:
Fully usable desktop — Bring it to the office, dock it with keyboard, mouse and external monitor. You can now use it as a regular PC running Visual Studio, Excel, and all that jazz!
Fully usable tablet — Bring it with you on the bus, and use it as a small, touch friendly browser and time waster, just like an iPad or Android tablet!
…in one device — Inspiration strikes? Switch back to your Visual Studio project and fix, test and commit while still on the bus.
Useful, new features — I’m sure tiles can come in handy on a desktop system, but on a tablet I think they’ll set a new standard for convenience.
No software limitations — Encounter something stupid, like not being able to run an app in the background, or not being able to search on a web page (looking at you, iPad!!)? You have a full desktop OS to fall back on!
Both toy and tool — It’s no longer just a fun but useless toy. Bittorrent a Ubuntu iso, checksum it, and write it out to a thumb drive? Sure thing!
Want to demo something? Want to script something? You got it.
I would ditch my iPad 2 in a second.
Seriously?
Seriously.
And yes, I think it will work in practice. You see, it already has:
I loved Maemo, the Debian based cell phone OS featuring xterm and a GNU toolset in the factory default. Like Windows 8, Maemo had a touch UI for normal operation, but also allowed you to go behind the scenes and run “proper” software.
While I obviously spent most of my time in the touch UI, Maemo was there for me when I needed more. Granted, not everyone feels they have to strip and encode the audio track from a youtube video on their phones, but the core point remains:
When someone with a modern, online, multi-gigabyte, multi-core tablet says “Oh darn, I can’t. I don’t have a computer with me”, something is tragically wrong.
And that’s why I can’t wait for Windows 8.
PS: I’ve written “Windows 8” a total of twenty-three times in this article. I promise that nothing like this will ever happen again.
How do I write a regex that matches lines that do not contain hi?
That’s a frequently asked question if I ever saw one.
Of course, the proper answer is: you don’t. You write a regex that does match hi and then invert the matching logic, ostensibly with grep -v. But where’s the fun in that?
One interesting theorem that pops up in any book or class on formal grammars is that regular languages are closed under complement: the inverse of a regular expression is also a regular expression. This means that writing inverted regular expressions is theoretically possible, though it turns out to be quite tricky
Just try writing a regex that matches strings that does not contain “hi”, and test it against “hi”, “hhi” and “ih”, “iih” and such variations. Some solutions are coming up.
A way to cheat is using PCRE negative lookahead: ^(?!.*foo) matches all strings not containing the substring “foo”. However, lookahead assertions require a stack, and thus can’t be modelled as a finite state machine. In other words, they don’t fit the mathematical definition of a regular expression, and therefore disqualify.
There are simple, well-known algorithms for turning regular expressions into non-deterministic finite automata, and from there to deterministic FA. Less commonly used and known are algorithms for inverting a DFA and for generating familiar textual regex from it.
What I had a harder time finding was software that actually did this. So here is a Haskell program. It’s highly suboptimal but it does the job. When executed, it will ask for a regex and will then output a grep command that matches everything the regex does not (without -v, obviously).
The expressions it produces are quite horrific; it’s computer generated code, after all.
A regular expression for matching strings that do not match .*hi.* could be grep -E '^([^h]|h+$|h+[^hi])*$'.
This app, however, suggests grep -E '^([^h]([^h]|)*||([^h][^h]*h|h)|([^h][^h]*(h(hh*[^hi]|[^hi]))|(h(hh*[^hi]|[^hi])))((hh*[^hi]|[^h])|)*|([^h][^h]*(h([^hi][^h]*h|h))|(h([^hi][^h]*h|h)))(([^hi][^h]*h|h)|)*)$'
It still works exactly as stated though!
The app just supports a small subset of regex, just enough to convince someone that it works, and as a party trick lets you answer the original question exactly as stated.
If you have a new installation, you’re probably using SHA512-based passwords instead of the older MD5-based passwords described in detail in the previous post, which I’ll assume you’ve read. sha512-crypt is very similar to md5-crypt, but with some interesting differences.
Since the implementation of sha512 is really less interesting than the comparison with md5-crypt, I’ll describe it by striking out the relevant parts of the md5-crypt description and writing in what sha512-crypt does instead.
Like md5-crypt, it can be divided into three phases. Initialization, loop, and finalization.
Generate a simple md5sha512 hash based on the salt and password
Loop 10005000 times, calculating a new sha512 hash based on the previous hash concatenated with alternatingly the hash of the password and the salt. Additionally, sha512-crypt allows you to specify a custom number of rounds, from 1000 to 999999999
Use a special base64 encoding on the final hash to create the password hash string
The main differences are the higher number of rounds, which can be user selected for better (or worse) security, the use of the hashed password and salt in each round, rather than the unhashed ones, and a few tweaks of the initialization step.
Here’s the real sha512-crypt initialization.
Let “password” be the user’s ascii password, “salt” the ascii salt (truncated to 816 chars) , and “magic” the string “$1$”
Start by computing the Alternate sum, sha512(password + salt + password)
Compute the Intermediate0 sum by hashing the concatenation of the following strings:
Password
Magic
Salt
length(password) bytes of the Alternate sum, repeated as necessary
For each bit in length(password), from low to high and stopping after the most significant set bit
If the bit is set, append a NUL bytethe Alternate sum
If it’s unset, append the first byte of the password
New: Let S_factor be 16 + the first byte of Intermediate0
New: Compute the S bytes, length(salt) bytes of sha512(salt, concatenated S_factor times).
New: Compute the P bytes, length(password) bytes of sha512(password), repeated as necessary
Step 3.5 — which was very strange in md5-crypt — now makes a little more sense. We also calculated the S bytes and P bytes, which from here on will be used just like salt and password was in md5-crypt.
From this point on, the calculations will only involve the passwordP bytes, saltS bytes, and the Intermediate0 sum. Now we loop 5000 times (by default), to stretch the algorithm.
For i = 0 to 4999 (inclusive), compute Intermediatei+1 by concatenating and hashing the following:
If i is even, Intermediatei
If i is odd, passwordP bytes
If i is not divisible by 3, saltS bytes
If i is not divisible by 7, passwordP bytes
If i is even, passwordP bytes
If i is odd, Intermediatei
At this point you don’t need Intermediatei anymore.
You will now have ended up with Intermediate5000. Let’s call this the Final sum. Since sha512 is 512bit, this is 64 bytes long.
The bytes will be rearranged, and then encoded as 86 ascii characters using the same base64 encoding as md5-crypt.
Output the magic, “$6$”
New: If using a custom number of rounds, output “rounds=12345$”
Output the salt
Output a “$” to separate the salt from the encrypted section
For each group of 6 bits (there’s 86 groups), starting with the least significant
Output the corresponding base64 character with this index
And yes, I do have a shell script for this as well: sha512crypt. This one takes about a minute to generate a hash, due to the higher number of rounds. However, it doesn’t support custom rounds.
I hope these two posts have provided an interesting look at two exceedingly common, but often overlooked, algorithms!